Vision
Jun 2, 2025
Every time your phone unlocks with your face or a robot avoids an obstacle, it’s relying on object detection. But how do computers learn to "see" and interpret the world around them?
Object Detection, in Plain Terms
Object detection is a field within computer vision that not only identifies objects in an image (such as "car" or "person") but also locates them by drawing bounding boxes around each one.
Unlike image classification, which only labels an image as a whole (e.g., "this is a dog"), object detection tells us:
"There are two dogs: one on the left, one in the center."
This ability to both detect and localize objects makes object detection essential in systems that require spatial awareness, including self-driving cars, medical imaging, warehouse automation, and augmented reality.

How It Works: Teaching Machines to See
Object detection is driven by deep learning, particularly by a class of models known as Convolutional Neural Networks (CNNs). Here’s a simplified breakdown of the process:
Step 1: See like a human
CNNs analyze an image in stages, detecting simple patterns first (like edges and textures), and combining them to recognize complex features (like faces or vehicles).
Step 2: Learn from examples
The model is trained on thousands of annotated images to understand what defines a "person," "bicycle," or "traffic light."
Step 3: Predict and locate
After training, the model is able to output both the class of each object and its position within the image using bounding boxes.

Choosing the Right Object Detection Model
Different detection models are optimized for different needs—speed, accuracy, scalability, or spatial detail. Here's a breakdown of the major architectures.
YOLOv8 (You Only Look Once)
Single-stage detector optimized for speed.
Best for: Real-time surveillance, checkout-free retail, mobile robotics.
Why use it: Ideal for low-latency scenarios where response time is critical.
Detectron2
Two-stage detector developed by Meta AI, based on Faster R-CNN.
Best for: Self-driving vehicles, medical diagnostics, precision manufacturing.
Why use it: When accuracy and segmentation detail are top priorities.
SSD (Single Shot MultiBox Detector)
Single-stage model using multiple feature maps.
Best for: Embedded systems, mobile applications.
Why use it: A balanced trade-off between YOLO’s speed and Faster R-CNN’s accuracy.
Faster R-CNN
Classic two-stage detector with region proposals.
Best for: Scientific imaging, document layout analysis.
Why use it: Excels at detecting small or overlapping objects in controlled environments.
EfficientDet
Scalable detector built on EfficientNet.
Best for: Cloud inference, edge deployment, evolving workloads.
Why use it: Adjustable variants (D0 to D7) allow tuning for both speed and accuracy.
CenterNet / CornerNet
Keypoint-based approaches that detect object centers or corners.
Best for: Human pose estimation, sports analysis.
Why use it: Ideal for applications where the internal structure or posture of objects matters.
DETR (Detection Transformer)
Transformer-based architecture from Meta AI.
Best for: Scene understanding, systems already using Transformers.
Why use it: End-to-end design without region proposals or anchors; aligns with modern vision-language pipelines.
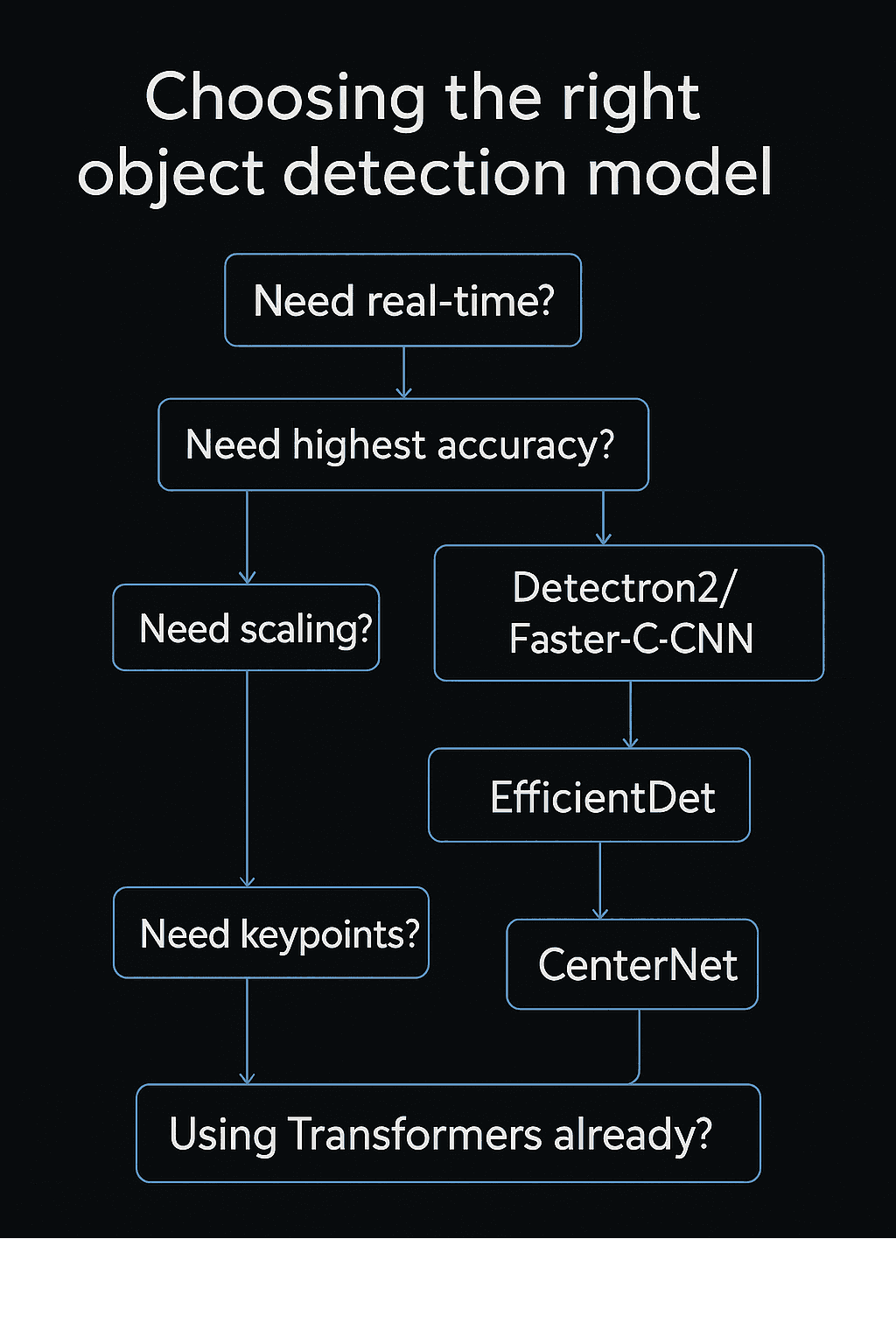
How to Choose: Model Selection Guide
Need real-time detection? Use YOLOv8 or SSD
Need highest accuracy and instance segmentation? Use Detectron2 or Faster R-CNN
Need model scalability and deployment flexibility? Use EfficientDet
Need spatial detail (e.g. keypoints or posture)? Use CenterNet or CornerNet
Already working with Transformers or NLP-vision pipelines? Use DETR
Timeline: Key Milestones in Object Detection
2012 – AlexNet introduces deep CNNs, winning ImageNet
2014 – R-CNN launches region-based object detection
2015 – Faster R-CNN introduces region proposal networks for faster performance
2016 – YOLO debuts as the first real-time detector
2017 – SSD and RetinaNet bring efficient single-shot methods
2019 – EfficientDet introduces compound scaling
2020 – DETR introduces Transformer-based detection
Common Challenges in Object Detection
False Positives/Negatives
Incorrect or missed detections due to low contrast, cluttered scenes, or class confusion.
Occlusion
Partially hidden objects are difficult to detect, especially in crowded environments.
Dataset Bias
Models trained on limited datasets may not generalize well to new environments or demographics.
Scale Variation
Objects of vastly different sizes in the same frame pose challenges to feature extraction.
Real-Time Constraints
Running detectors on low-power or edge hardware remains a challenge for high-fidelity models.

Real-World Applications
Smart checkout systems
YOLOv8: Real-time object recognition on embedded cameras.
Urban autonomous driving
Detectron2: Precise segmentation in complex and crowded environments.
Drone navigation
YOLOv8 or SSD: Lightweight models for real-time inference on edge devices.
Industrial quality control
Detectron2: Identifies subtle defects and ensures consistent production quality.
Fitness tracking apps
CenterNet: Estimates human posture with keypoint detection.
Medical imaging (e.g. MRI tumor detection)
Faster R-CNN: Accurate detection of small and complex biological features.
Cloud-based dashboards
EfficientDet: Scalable inference with tunable speed/accuracy tradeoffs.
Scene graph generation
DETR: Integrates vision and context for semantic reasoning.
What’s Next: Emerging Trends
Multimodal vision models that combine image, text, and audio understanding
Zero-shot detection using foundation models like CLIP and DINO
Diffusion-based object detection (early-stage research, high precision potential)
Unsupervised or weakly supervised labeling techniques
Real-time, on-device detectors powered by TinyML
Final Thoughts
Object detection is now a foundational capability in modern AI systems, from unlocking phones to navigating self-driving cars. But choosing the right detection model is not just a technical decision, it’s a strategic one.
Understanding the trade-offs between speed, accuracy, and scalability helps ensure your product "sees" the world in the way that matters most.
Let the model match the mission.