Deep Learning
May 21, 2025
When Deep Learning Beats Traditional Machine Learning is a concise guide to modern credit risk modeling. It explains how deep learning, with its ability to analyze raw and complex data, is increasingly outperforming traditional models like logistic regression and decision trees. Through clear examples, it highlights when and why deep learning makes sense, the evolving role of feature engineering, and how interpretability tools now enable transparency in AI-driven financial decisions.
What This Is About
Imagine you are evaluating a loan application. You have access to data like income, age, missed payments, and loan amount. Your job is to decide: is this person likely to repay?
This process is known as credit risk modeling. It uses historical data to estimate the likelihood that someone will default on a loan. For many years, traditional machine learning models such as logistic regression and decision trees have performed this task reliably. These models depend on clearly defined rules and features created by humans.
However, the lending landscape is changing. Lenders now deal with more data, more behavioral signals, and increasingly complex borrower profiles. In this environment, traditional models often struggle to keep up. Deep learning provides a more flexible and powerful alternative.
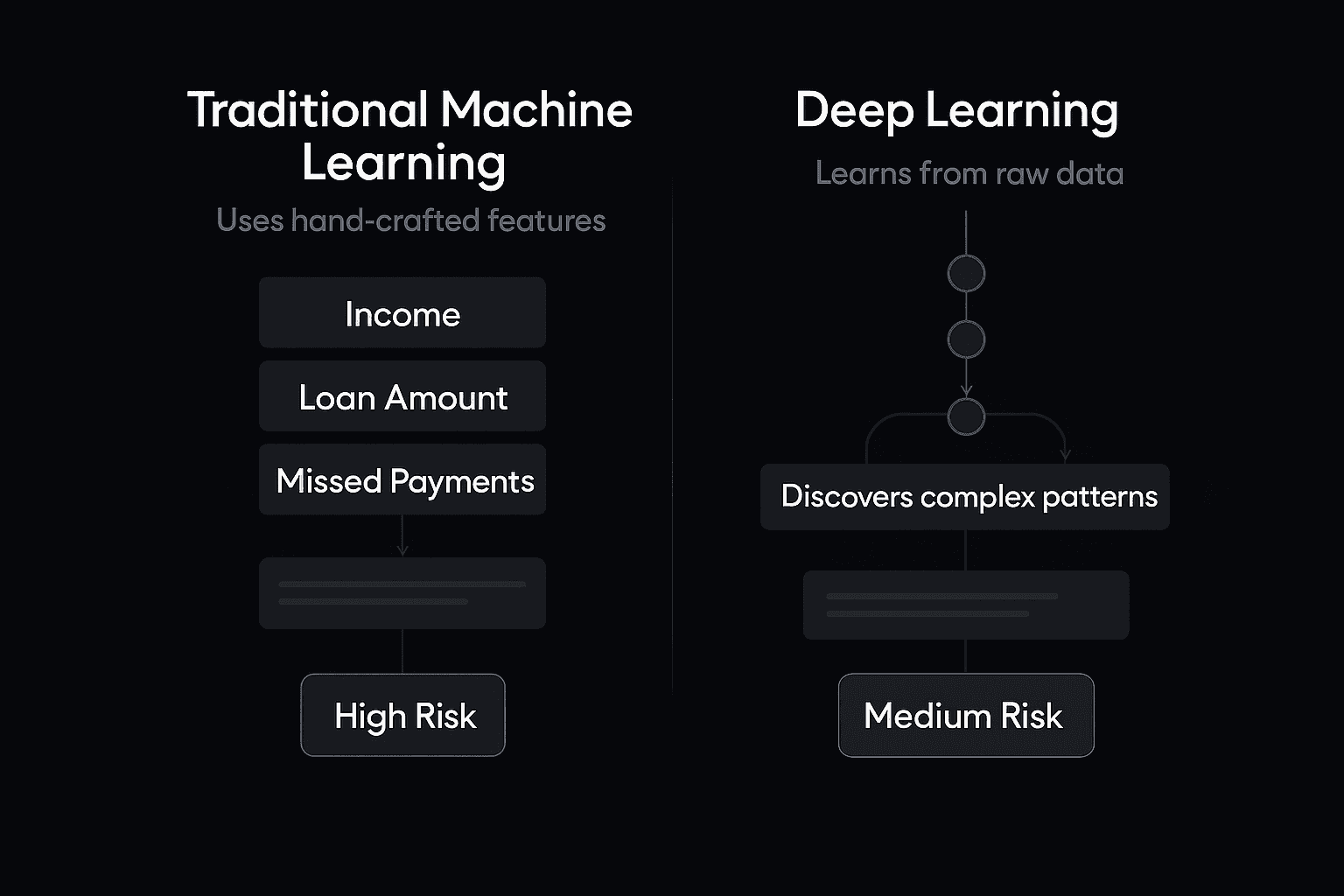
The visual above compares both approaches. Traditional models rely on a handful of selected inputs. Deep learning models analyze raw and often messy data, revealing patterns that are not immediately obvious.
Traditional Machine Learning: Clear Rules, Human Effort
Traditional models rely on structured inputs crafted by data scientists. These inputs, called features, are often designed based on known risk indicators or business logic.
For example, a model might use:
Number of missed payments in the last six months
Debt-to-income ratio
Frequency of recent loan applications
These features are used to predict whether a borrower is high or low risk.

This approach is transparent and relatively simple to deploy. However, it depends heavily on the quality of manual work done upfront. As the volume and variety of data increases, these models often lose their effectiveness.
If a feature is not explicitly defined in advance, the model will never consider it, no matter how important it might be.
How Deep Learning Is Different
Deep learning models, like neural networks, work differently. They can process raw inputs directly, such as transaction records, merchant IDs, time patterns, or customer histories. They do not require each input to be converted into a neat feature beforehand.
Deep learning is especially useful when:
The data is high-dimensional or noisy
The relationships between inputs are complex or nonlinear
Behavior evolves over time and varies by segment
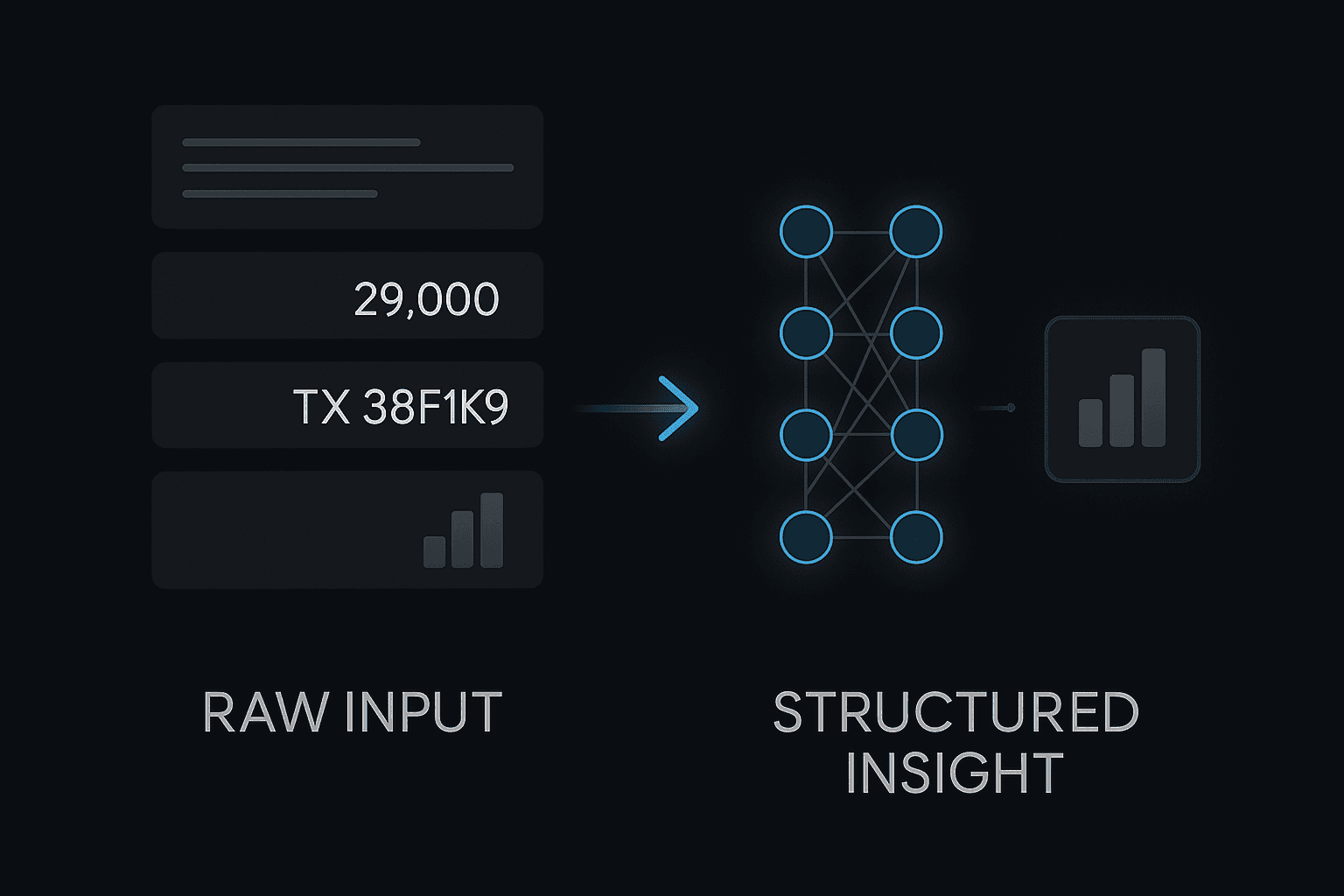
For example, a deep learning model can learn that certain types of transactions late at night are linked to higher repayment risk only when combined with recent increases in loan size. These relationships are too complex to define manually. The model builds its own layered understanding of what matters.
Instead of reducing the model’s dependence on features, this approach expands what it can learn and makes use of patterns that humans would never think to create.
A Practical Example
Consider a borrower with this profile:
Income: $5,000
Age: 28
Merchant Type: Grocery
Missed Payments: 1
Loan Amount: $2,000
A traditional model might assign a high risk score due to the missed payment or the loan size. However, it does not consider the broader behavioral context.
A deep learning model, trained on many similar borrowers, might recognize that people with this pattern tend to repay their loans. The combination of merchant type, age, and spending habits may actually lower the overall risk. This leads to a prediction that is more fair and often more accurate.
Interpretability: Making Complex Models Understandable
Deep learning has historically been seen as difficult to interpret. However, that perception is changing. Modern tools make it easier to understand what a deep model is doing.
Techniques such as SHAP values, saliency maps, and attention scoring allow teams to:
Identify the features that contributed most to a prediction
Compare model reasoning across different borrower profiles
Audit predictions for fairness, reliability, and risk

This kind of transparency is essential in financial services. Stakeholders need to understand how decisions are made, especially when regulations require explanations for why a loan was approved or denied.
When Deep Learning Makes Sense
Deep learning is not always the right answer. For clean and limited datasets with clear rules, traditional models often perform well and are easier to interpret.
But deep learning becomes the better choice when:
You are working with a large and varied dataset
You want to reduce manual effort in feature creation
You need to capture subtle behavioral or sequential patterns
Your current model’s performance has plateaued despite more tuning
In credit risk, these conditions are becoming more common. The result is smarter models that are better at distinguishing between good borrowers and bad ones.
The Role of Feature Engineering Today
Feature engineering still matters, but its role has changed. Instead of being the main source of model intelligence, features now serve as helpful signals. The model itself does much of the heavy lifting.
Rather than defining rules like "two missed payments plus high loan amount equals high risk," the model learns how risk levels vary across different combinations of factors. It does so by comparing thousands of examples and adjusting its internal understanding.
This allows teams to focus on strategy and model governance rather than spending time rewriting rules or rebuilding manual inputs.
Key Takeaways
Deep learning models are outperforming traditional models in credit risk prediction when the data is large or complex.
These models reduce reliance on manual feature engineering by learning directly from raw inputs.
Interpretability tools now make it possible to audit and explain deep learning predictions in a meaningful way.
Choosing the right modeling approach depends on your data size, model goals, and need for clarity or flexibility.